Velký jazykový model
Někdy o něm také můžeme číst jako o LLM (Large Language Model). Je to sofistikovaný počítačový program, který je určen k analýze a generování textu. Může být využit například pro strojový překlad, rozpoznávání řeči, generování odpovědí apod.
LLM jsou trénovány na obrovském množství textů, kterým se říká korpusy. To mohou být třeba digitalizované knihy, články, obsah Wikipedie a další. Takto se například vyvíjel model GPT [zdroj]:
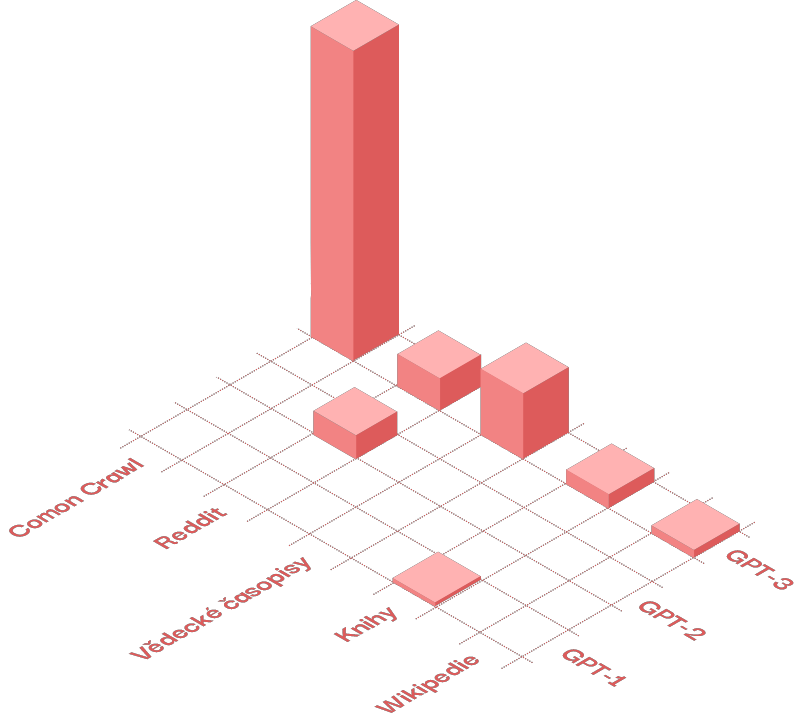
Knižní korpus GPT-1
Romantické knihy: 26,1 %
Fantasy: 13,6 %
Sci-fi: 7,5 %
Pro dospívající: 6,8 %
Thriller: 5,9 %
Knihy o upírech: 5,4 %
Mysteriózní: 5,6 %
Další...
Common Crawl
Databáze Common Crawl je veřejně dostupný archiv webových stránek. Je vytvářen pravidelným procházením (crawlováním) webu a ukládáním obsahu.
Na obrázku vidíme korpusy, na nichž byly natrénovány jednotlivé verze modelu GPT. Výška kvádrů je poměrné množství dat.
Velké jazykové modely mají svou vnitřní reprezentaci našeho světa. Je vytvořena pomocí tzv. vektorů. Představte si model jako obrovský mnohodimenzionální prostor, v němž každé slovo (token) má svou přesnou polohu. Té se říká vektor a můžete si ho představit jako souřadnici. Různá slova mají k sobě v různých kontextech blíže než k jiným.
Například když napíšete do chatbota zadání (tzv. prompt):
Vygeneruj recept na volské oko.
slovo „oko“ se bude nacházet v tomto kontextu jinde, než když napíšete:
Popiš, jak vzniká obraz na sítnici oka.
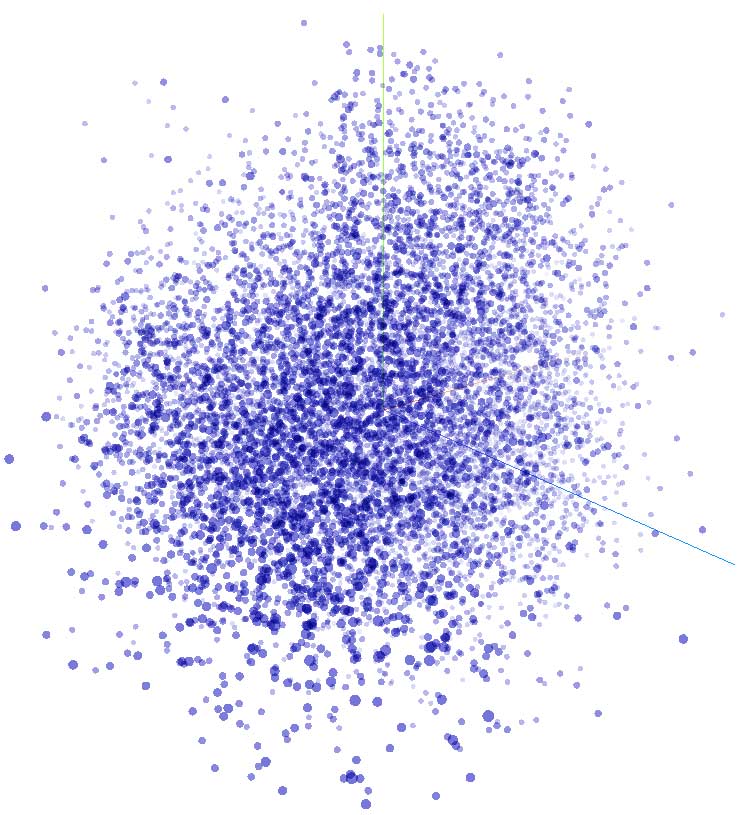
Propojení mezi slovy
Zjednodušenou vizualizaci propojení slov (tokenů) si můžete prohlédnout třeba v aplikaci Embedding Projector. Najeďte myší na jednotlivé body a uvidíte slova. Když na bod kliknete, zobrazí se sémanticky podobné výrazy.
To, co se děje ve velkém jazykovém modelu po vložení pár tokenů, můžete vidět zase v aplikaci AnimatedLLM.
Na světě je velkých jazykových modelů jen několik a jsou z důvodů nároků na počítačový hardware vytvářeny hlavně velkými společnostmi. V současnosti jsou nejznámější GPT (OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta) nebo LaMDA (DeepMind) nebo třeba DeepSeek (Hangzhou).
Proces vzniku velkého jazykového modelu může být (velmi zjednodušeně) rozdělen do tří kroků:
+ výběr korpusů: ty by měly být dostatečně velké a rozmanité,
+ trénování modelu: model je trénován na datech pomocí algoritmů strojového učení,
+ validace a testování: model je zkoušen na datech mimo trénovací sadu, upravován a dále vylepšován.
Nakonec je model nasazen pro reálné použití, například pro vedení konverzace (chatboti), překlad textů nebo jiné aplikace. K tomu je třeba zajistit, aby se chatbot dobře choval k uživatelům a nikomu neublížil.