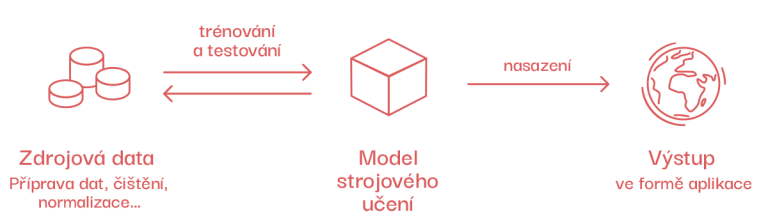
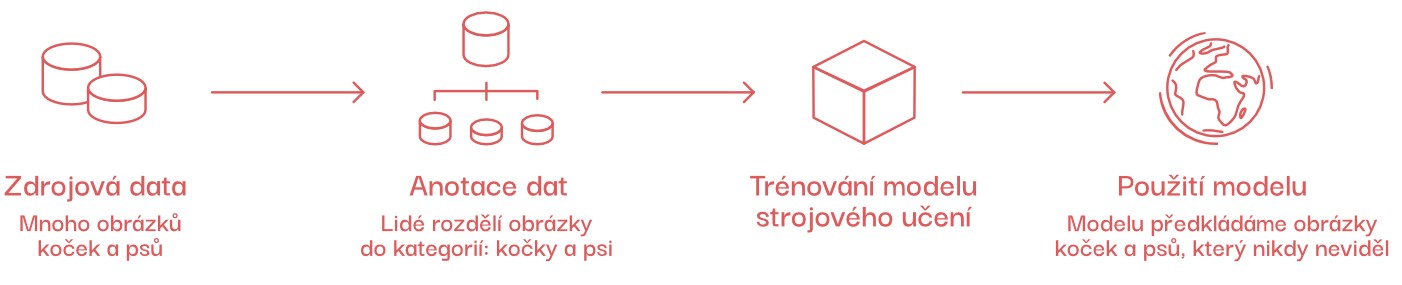
Pokud bychom chtěli vytvořit pomocí tohoto typu strojového učení aplikaci, která rozpoznává psy a kočky, museli bychom nejdříve systému umělé inteligence říci, na kterých obrázcích jsou kočky a na kterých psi (tzv. anotovat data). Lidé tedy plní úlohu učitelů, podle čehož se tento přístup nazývá.
Po rozdělení obrázků na kočky a psy bychom natrénovali model strojového učení a poté bychom mu ukazovali obrázky koček a psů, které ještě nikdy neviděl.
Sledovali bychom, zda zvíře určil správně. Pokud ne, vylepšili bychom datovou sadu a natrénovali model znovu.
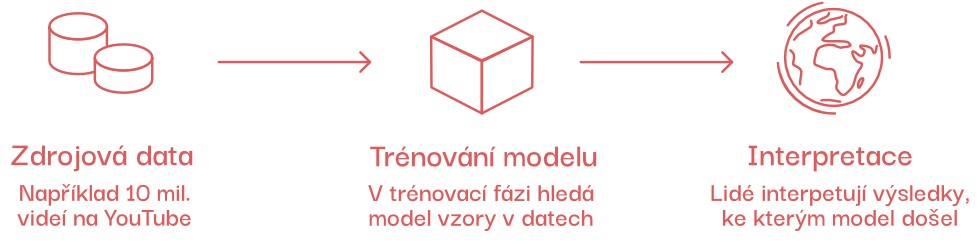
Někdy může být velmi zdlouhavé, nákladné či přímo nemožné všechna data anotovat. V takových případech využíváme strojové učení bez učitele.
Tento typ programu si vyhledává podobnosti (vzory) sám a vstupní data poté dokáže rozdělit do shluků (anglicky cluster), abychom se v datech my lidé lépe vyznali — a především pak snadno určili, co který shluk znamená.
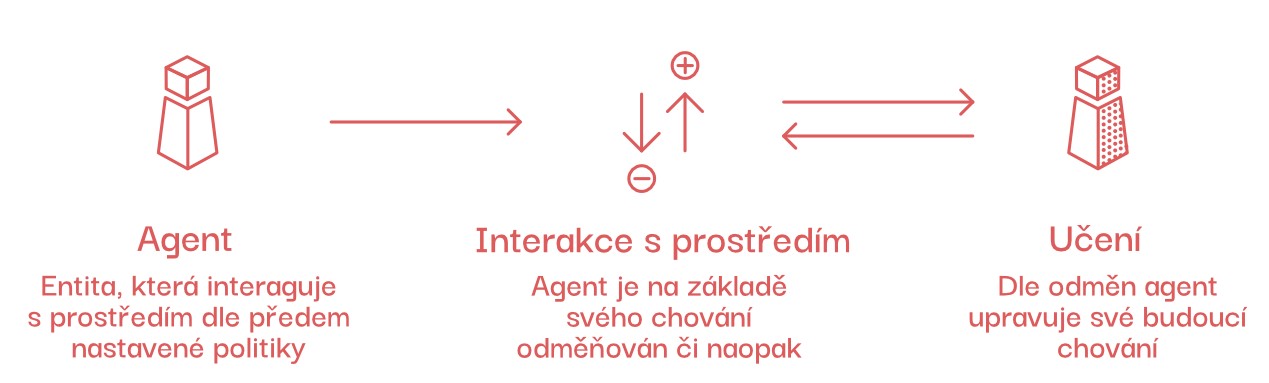
Někdy necháme stroje, aby něco zkoušely samy (metodou pokus/omyl), a následně jim dáváme zpětnou vazbu skrze tzv. politiky. Stroje si na základě zpětné vazby (skrze politiky) vyvíjejí strategie chování.