Kosatce v náhodném lese
O procházkách loukami, datech, strojovém učení a generativní umělé inteligenci
Autor: Ondřej Michalák
Editorka: Eva Nečasová
Syntetické obrazy: Lenka Hámošová
Slavný britský biolog a statistik Ronald Fisher si téměř před sto lety položil otázku, zda by z délky či šířky okvětních či jiných lístků šlo rozlišit různé druhy květin. V případě kosatců (irisů) měl štěstí — Edgar Anderson předtím naměřil a vytvořil dodnes známý soupis popisující tři druhy kosatců, z nichž každý obsahoval padesát naměřených vzorků.

versicolor

setosa

virginica
Všimněme si, že i když jsou si kosatce podobné, liší se v mnoha znacích. Anderson se zaměřil na délky a šířky kalichů a okvětních lístků a u každé naměřené kombinace uvedl druh. Tomuto třídění (případně klasifikaci) budeme říkat anotace. Kdyby mu nějaký kolega, který se v kosatcích nevyzná, donesl dalších padesát měření, pan Anderson by mu musel nové záznamy rozpoznat a anotovat — tedy popsat, které číselné záznamy patří k jakému druhu.
Anotace je základní disciplína při přípravě dat pro strojové učení, kde člověk k datovému záznamu přiřazuje jeho význam. Nejčastěji se anotují obrázky, kde člověk popisuje objekty, které jsou na obrázku, ale stejně tak lze anotovat sentiment textu či emoce při poslechu hudby. Význam anotací je natolik důležitý, že na nich pracují celé týmy po celém světě. Anotaci běžných lidských věcí umí dělat téměř kdokoliv, a protože je to disciplína snadná a placená, často se dělá v rozvojových zemích za podmínek podobných otroctví. Ne všechna data pro strojové učení se musí anotovat — anotuje se jen tam, kde nám nějaká informace chybí a musí být dodána typicky člověkem.
Následuje ukázka takovéto anotace, tedy soupisu naměřených dat kosatců, která v originále obsahuje 150 záznamů (50 pro každý druh). Jednotky jsou v cm:
Kalich (délka)
Kalich (šířka)
Okvětní (délka)
Okvětní (šířka)
Druh kosatce
5,1
3,5
1,4
0,2
setosa
5
3,6
1,4
0,3
setosa
...
setosa
6,4
3,2
4,5
1,5
versicolor
5,5
3,2
4
1,3
versicolor
...
versicolor
5,8
2,8
5,1
2,4
virginica
5,6
2,8
4,9
2,0
virginica
...
virginica
Takovémuto soupisu říkáme odborně dataset. Datasety obecně jsou množiny dat, často ve formě tabulek, ale můžou mít i jiné tvary a formáty, které dokáží popsat i netabulkové struktury dat. Při některých typech strojového učení je dataset zcela zásadní pro trénování systémů umělé inteligence.
Položme si nyní zásadní otázku: Kdybych šel po louce a změřil si lístky náhodného kosatce, dokázal bych podle tabulky určit, o jaký se jedná druh?
Nevím, jak vy, ale já osobně bych se topil v záplavě čísel. Když mi bude při porovnávání sedět jedno číslo, ostatní mi odpovídat nemusí. Poctivě porovnat mé měření se sto padesáti jinými je také celkem náročné cvičení. Také vím, že kosatců je na světě přes dvě stě druhů. Kdybych měl od každého druhu padesát měření, moje tabulka by měla nejméně deset tisíc řádků. Navíc si nejsem jist, zda bych poznal, jestli je porovnávám ve správném okamžiku jejich životního cyklu.
Zkušený botanik by se nejspíš u několika druhů bez tabulky obešel. Kosatec by určil na základě zkušeností. Poznal by ale také druhy, které se nevyskytují v regionu, jenž zná?
Umělá inteligence bez počítače
Na pomoc nám přicházejí postupy, které si z tabulky dat umí s pomocí matematických struktur vytvořit vlastní reprezentaci. Přístupů, jak na to, je mnoho. Na vysvětlenou si můžeme vzít tzv. rozhodovací strom. Ronald Fisher sice vynalezl jinou metodu, ale ta není pro první seznámení tak názorná. Pojďme se na jeden rozhodovací strom podívat. Tento bychom s trochou práce zvládli i s tužkou a papírem:
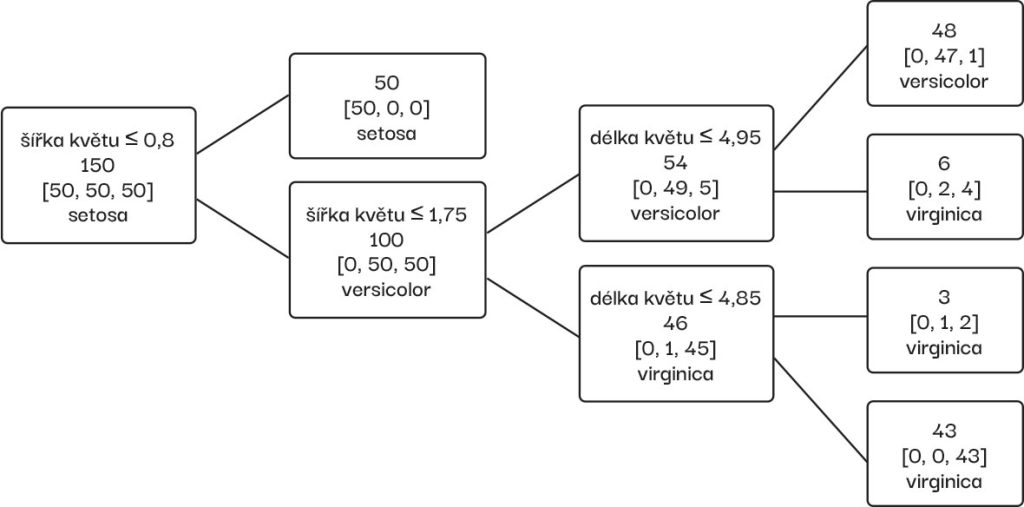
V případě tohoto konkrétního stromu si nejdříve rozdělíme tabulku podle šířky okvětního lístku. V případě, že je menší nebo rovna 0,8 cm, hned vidíme, že jde o kosatec druhu setosa, protože v datasetu jsou s touto vlastností všechny jen druh setosa. V případě, že je větší, se obdobně musíme rozhodovat dál. Všimněme si, že kdybychom si hned na začátku neporovnávali hodnotu 0,8 cm, ale větší, nejspíš by se nám to dále větvilo.

Pokud bychom chtěli hned na začátku třídit podle jiného atributu, např. podle výšky kalichu, rozhodovací strom by vypadal úplně jinak. Můžete si zkusit udělat vlastní rozhodovací strom, jeho sestavení je jednoduché. Vyberte si atribut a u něj třeba aritmetický průměr, medián jeho hodnot nebo náhodnou hodnotu z daného rozsahu, a tak založíte první rozhodovací uzel stromu (ve smyslu větší/menší než daná hodnota, kterou jste zvolili) a nad zbylými daty pokračujete v každé větvi dál. Způsobů, jak správně takový strom sestavit, je obrovské množství.
K čemu je nám ale takový strom vlastně dobrý? Vraťme se k předchozímu příkladu, kdy při naší procházce loukou změříme jeden kosatec. S naměřenými hodnotami mohu procházet díky porovnání čísel stromem, až dojdu k určení daného kosatce! Najednou i já, který se v kosatcích vůbec nevyznám, dokážu určit druh s pomocí rozhodovacího stromu! Dříve se tomu tak neříkalo, ale dnes i díky mediálnímu harašení bychom řekli, že jsme právě k určení druhu kosatce použili predikci umělé inteligence. Bez počítače. Navíc o vlastním sestavení stromu můžeme říkat, že jsme vytvořili či natrénovali model umělé inteligence na základě dat. V našem případě model třídí záznamy dle druhů, tedy klasifikuje, tak mu také můžeme říkat klasifikátor. Umíte si představit vytvoření klasifikátoru bez dat?
Jak je takový strom přesný
Pokud k sestavení stromu použiji všechny dostupné záznamy a budu rozhodovací uzly stavět do maximální možné hloubky, bude tento strom pro všechny tyto záznamy naprosto přesný. Když ale naměřím novou rostlinu, kterou mi nikdo nepomáhal anotovat, nemám žádný prostředek, jak si přesnost určení ověřit.
Abychom měli alespoň nějakou možnost určení přesnosti, uděláme takový trik. Odstraníme z datasetu nějaký náhodný a reprezentativní vzorek dat. Typicky to může být např. 5—20 %, tedy v našem případě třeba třicet záznamů. Tyto záznamy si necháme stranou a nepoužijeme je k sestavení stromu. Budeme jim říkat testovací záznamy.
Strom nám pak ze zbylé množiny dat nejspíš vyjde trochu jinak, ale můžeme si jeho přesnost otestovat právě těmi záznamy, které jsme nepoužili k sestavení stromu. Máme je předem určené, a pokud je náš strom vyhodnotí špatně, sníží nám to přesnost modelu. Koho by přesnost zajímala do většího detailu, může si něco přečíst o matici záměn, která pěkně ukazuje, jakých druhů chyb se náš model nejčastěji dopouští. Protože je přesnost modelu jeho naprosto zásadní vlastnosti, existuje celá řada matematických přístupů, jak přesnost měřit a vyjadřovat. Jejich popis je ale nad rámec složitosti tohoto textu.
Matici záměn či další indikátory přesnosti, které se rozhodneme využít, můžeme považovat za data. Pro vylepšování modelu se bez nich neobejdeme. Musíme s nimi tedy nakládat jako s daty.
Je důležité si uvědomit, že strom byl sestaven na základě dat. Čím více reprezentativních dat budeme mít, tím lepší může být přesnost našeho stromu. Pokud od jednoho druhu sebereme méně dat, nebo např. jen nález kosatců z jednoho plácku s mnoha podobnými parametry, nepomůže to přesnosti modelu, se kterým máme větší ambice.

Kde nám pomohou počítače
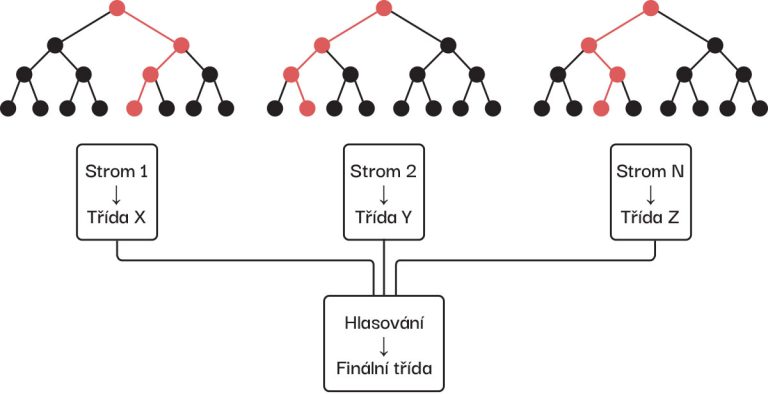
Již bylo řečeno, že strom je možné sestavit různě a že také můžeme určit jeho přesnost. Díky počítačovým programům mohu ale generovat stovky, tisíce či miliony takových stromů — vlastně takové náhodné lesy — a z nich pak pro rozhodování vybrat jen jeden strom, který má nejvyšší přesnost. Nebo také několik, které pak o výsledku rozhodnou „hlasováním“. Známý algoritmus, který funguje na tomto principu, se proto jmenuje Náhodný les.
Parametry
Všimněte si — rozhodovací strom v naší ukázce se nám hezky vešel na obrazovku a stihli jsme jej přečíst během pár minut. Jenže ve skutečnosti, když takový strom vytváří počítač, může být struktura stromu mnohonásobně větší a složitější. Sestavit jej z dat může zabrat nějaký ten čas. I menší stromy mohou být časově náročné, protože je počítač musí najít na základě vyhodnocení jejich přesnosti. Velké složité modely se počítají i desítky tisíc hodin.
Kdybych nechal počítač hloubat nad nepřebernými kombinacemi, mohlo by to trvat věčnost. Takový výpočet není ani ekonomický, ani ekologický.
Abychom výpočet nějak zpřesnili či omezili, použijeme tedy tzv. parametry. Každý typ algoritmu má svou sadu parametrů. U rozhodovacího stromu si můžu nastavit např. tzv. hloubku stromu, tedy kolik rozhodnutí mohu mít maximálně v řadě za sebou. Případně zda rozhodovací podmínka bude volit náhodně, nebo dle nějakého předem daného postupu. Takových parametrů jsou desítky.
Protože nám různé kombinace parametrů budou dávat různé výsledky ve smyslu přesnosti modelu či délky výpočtu, často používáme velmi mazané postupy na odhalení těch nejlepších. I na jejich hledání je možné využít umělou inteligenci. Můžeme pak říct, že AI zkoumá AI.
I parametry jsou data a mají na funkci algoritmu naprosto zásadní vliv.
Generativní AI
Pojďme se ještě na chvilku vrátit k rozhodovacímu stromu. Podíváme-li se na něj zprava a budeme postupovat doleva, strom nám může generovat kosatce (ve smyslu jejich naměřených hodnot v tabulce výše) dle požadovaného druhu. Řekněme, že si budeme chtít vytvořit např. setosu. Pak nám stačí zvolit náhodné číslo pro šířku okvětního lístku do 0,8 cm a dle našeho modelu bude splněna podmínka, i když třeba výšku kalichu náhodně vybereme minus pět metrů. Je to samozřejmě krajně absurdní případ. Hodnoty všech čtyř atributů bychom nejspíše volili náhodně tak, aby byly v rozsahu hodnot v tabulce a splňovaly podmínky na uzlech při přechodu zprava doleva. To, zda generované hodnoty skutečně odpovídají požadovanému druhu, si mohou fajnšmekři ověřit tím, že si jej následně klasifikují pro ověření správnosti.

A jak je to s obrázky a zvuky?
I obrázky a zvuky jsou data. Pokud bychom chtěli rozpoznávat kosatce dle fotek, i to by bylo možné, jen bychom potřebovali použít složitější algoritmy. Jinak bychom dodrželi stejný postup, který má ale pár kroků navíc v podobě přípravy dat. Ke stovkám fotek bychom připsali, o jaký druh kosatce jde — o anotaci už jsme si napsali výše. V případě obrázků nám různé úhly fotek stejné rostliny vytváří datově úplně jiné obrázky. Pootočením fotky ale zůstane kosatec kosatcem, a tak bychom si vygenerovali i různě pootočené fotky, které jsme ale uměle vytvořili. V takovém případě mluvíme o uměle vytvořených či syntetických datech.
Takto rozšířenou množinu obrázků bychom pak standardizovali jednak zmenšením a jednak sladěním rozměrů, aby měla každá fotografie stejnou velikost. Následně jednotlivé pixely obrázku převedeme na číselnou posloupnost a přidáme k ní kód anotované rostliny. Místo rozhodovacích stromů by se v praxi použily neuronové sítě, ale i rozhodovací strom by nám teoreticky fungoval, jen by byl výpočet pro uspokojivou přesnost nesmírně náročný. Pro menší obrázky, např. rozpoznávání jednotlivých znaků textu, by nám ale rozhodovací stromy mohly stačit.
Co se týká zvuků, kosatce obvykle nezvučí, ale kdybychom nahrávali šelesty větru uvnitř kalichu a následně zvuk převedli na číselnou řadu, možná by nás překvapilo, že by i takové určení druhu bylo možné, ale je to jen takové zamyšlení. Umělá inteligence v analýze zvuku má celou řadu jiných uplatnění. Pokud si nahrajete zvuk správně fungujícího stroje a pak zvuky při různých poruchách, můžete si natrénovat klasifikátor, který odhalí závadu dle zvuku. Všichni také známe doporučování hudby na základě toho, čemu jsme dali „lajk“. Píseň se dá převést do dat podle tónů apod. a „lajkem“ označené a neoznačené písně nám pak pomůžou natrénovat klasifikátor dle našeho vkusu. I když v tomto případě pomáhají také metadata, např. štítky žánrů, jazyka, hlasitosti apod. Nebo třeba informace o tom, zda jsme skladbu doposlouchali, než jsme přešli na jinou.
Závěrem
Tabulky, texty, obrázky či zvuky jsou data. Parametry či indikátory přesnosti jejich modelů jsou data. Pokud ale využijeme pro trénink klasifikátoru data neúplná nebo nesprávná, bude se pak chovat vzhledem k očekávání i samotný klasifikátor nesprávně a můžeme pak mít dojem, že je umělá inteligence předpojatá. O tom ale jindy.

AI dětem, z.s.
IČ: 17914582
Datovka: 4czjq6u
Číslo účtu: 2002446742/2010
Poptáváte vzdělávací akci či spolupráci?
Ozvěte se Kláře na: klara@aidetem.cz
Další kontakty naleznete v sekci Lidé.