

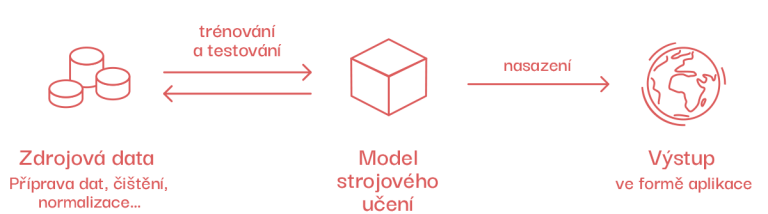
Představme si, že chceme naučit počítač rozpoznávat čísla 5 a 8. Jak by se lišil postup v případně algoritmického přístupu a strojového učení?
Algoritmický přístup
Čísla 5 a 8, jak je známe například z kalkulačky, bychom mohli strojům popsat pomocí této tabulky:
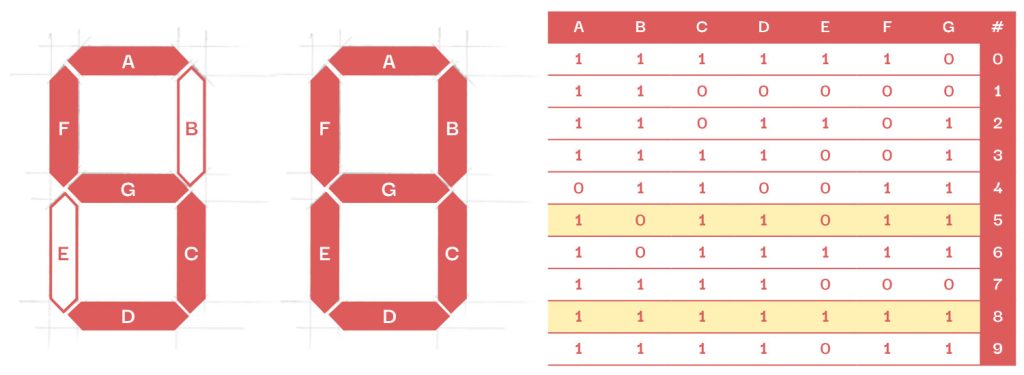
Plošky, které svítí (jsou červené), jsou v tabulce reprezentovány jako číslo 1. Plošky, které nesvítí, jako číslo 0. Jenomže pracujeme-li s takto přesnou definicí, náš program pochopitelně selže, pokud mu následně ukážeme ručně psané číslice.
Ba co víc, takový program dokonce nedokáže pracovat s jinou reprezentací dat, než je sedm jedniček a nul.
Strojové učení
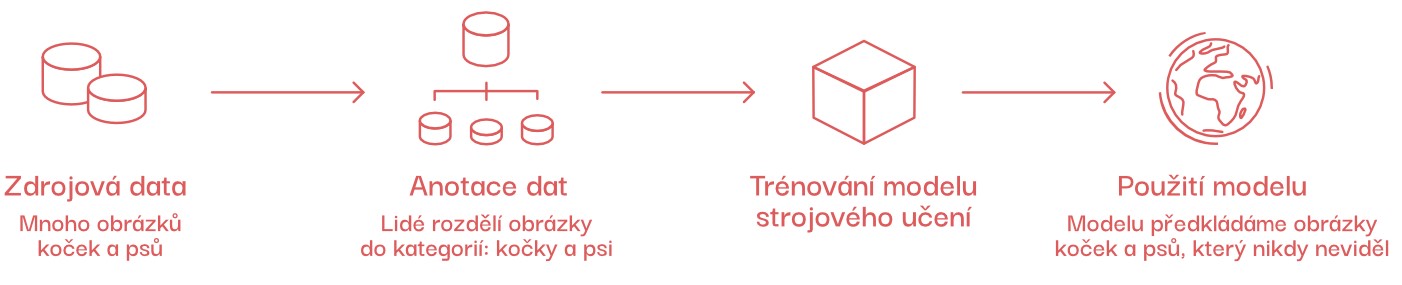
V rámci tohoto přístupu bychom programu ukázali velké množství obrázků číslic, ze kterých by si vytvořil vlastní reprezentace sám. Například takto:

Toto je ukázka datasetu MNIST — 70 000 číslic, ze kterých se programy strojového učení (modely) učí rozpoznávat číslice.
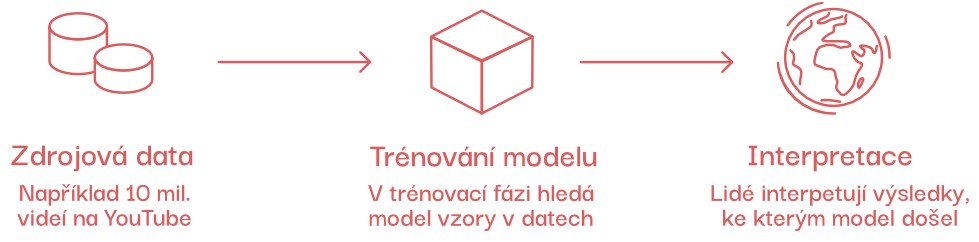
Je zřejmé, že tento přístup je mnohem složitější. Namísto sepsání několika jednoduchých pravidel musíme trénovat model (vlastně metodou pokusu a omylu, viz níže) na velkém množství dat, která předtím musíme sesbírat a označit.
Obrovskou výhodou ale je, že výsledný model bude — na rozdíl od algoritmického přístupu — fungovat na různě napsaných číslicích.
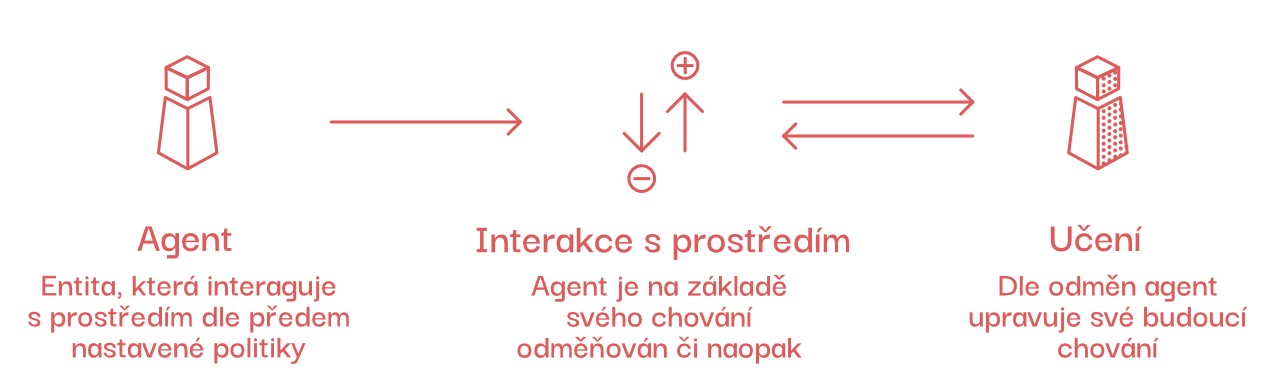

Přestože první umělý neuron byl vytvořen již v roce 1943, muselo lidstvo na svou první neuronovou síť čekat až do padesátých let 20. století. Vytvořil ji inženýr Frank Rosenblatt a nazval ji Mark I perceptron. Tato síť obsahovala jediný perceptron (umělý neuron).
Představte si ji jako jednoduchou elektronickou „mysl“, která se snaží rozhodnout, zda něco patří do jedné kategorie, nebo do druhé, na základě vstupních dat. Funguje tak, že přijímá informace (čísla), váží je podle určitého kritéria a poté rozhodne, do jaké kategorie data patří. Pokud se při prvním pokusu nerozhodne správně, upraví svá kritéria a zkusí to znovu, dokud se nenaučí rozhodovat správně.
Dnes už používáme sítě mnohem větší. Například hluboké neuronové sítě, které stojí za velkými jazykovými nebo obrazovými modely, mohou mít až biliony neuronů.

Hans byl kůň žijící na přelomu 19. a 20. století v Německu. Proslavil se svou mimořádnou inteligencí. Údajně byl schopen řešit aritmetické úlohy, číst a rozumět německému jazyku (odpovídal bušením kopytem o zem). Vystupoval s ním jeho majitel Wilhelm von Osten — učitel matematiky a amatérský výzkumník.
Vzhledem k výjimečným schopnostem, které Hans projevoval, se na něj upnula pozornost široké veřejnosti i vědecké komunity. V roce 1907 byla vytvořena komise, složená z expertů z různých oborů, která měla zkoumat jeho schopnosti.
Výzkumníci provedli řadu experimentů a zjistili, že Hans dokázal odpovědět na 89 % otázek správně, když jeho trenér von Osten na otázku odpověď znal. Ale v případě, že ji neznal, Hans odpověděl správně pouze na 6 % otázek.
Komise dospěla k závěru, že kůň reagoval na nevědomé pohyby a signály von Ostena, například pohyby hlavy nebo změny výrazu obličeje. Jednalo se o takzvaný Clever Hans effect či ideomotorický efekt.
Tento příklad velmi dobře ilustruje koncept strojového učení a předpojatosti. Von Osten byl „konstruktérem“ Hansovy inteligence, ale jeho porozumění způsobu, jak se kůň učí, bylo mylné. Podobné je to i s lidským pochopením toho, jak systémy AI interpretují data, na kterých byly natrénovány.

Legrační ukázkou předpojatosti je také obrázek generovaný pomocí umělé inteligence — konkrétně pro zadání (prompt) losos v peřejích (původně „salmon in a river“). Podobné mýlky vznikají jednoduše proto, že generativní model, který obrázek vytvořil, byl natrénovaný na datech, kde byl losos reprezentován častěji jako steak než jako ryba.
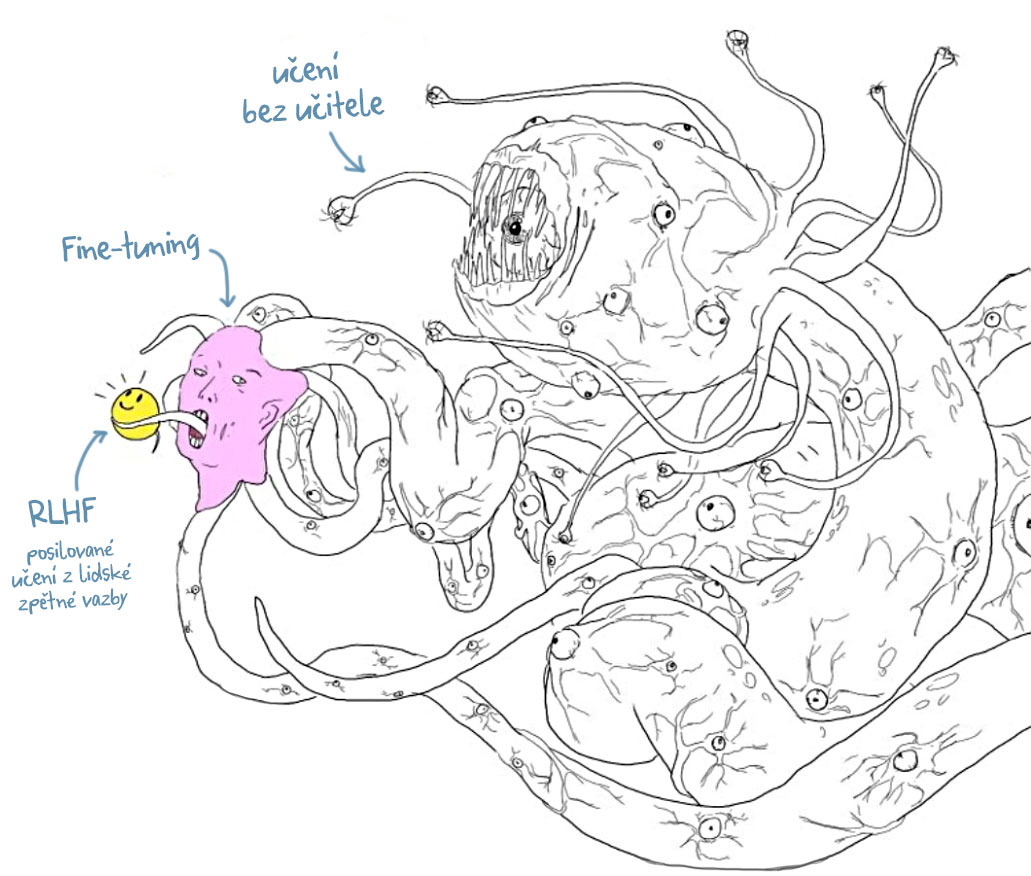
Velké zvíře na obrázku znázorňuje všechna data, na kterých byl GPT natrénován. S nadsázkou se ale my uživatelé bavíme pouze se žlutým sluníčkem. Tedy částí, která „nepapouškuje“ neetické nebo například nebezpečné věci. Vývojáře to stálo velké množství času a financí.
Zdroj obrázku: neznámý kreativec, X (Twitter)
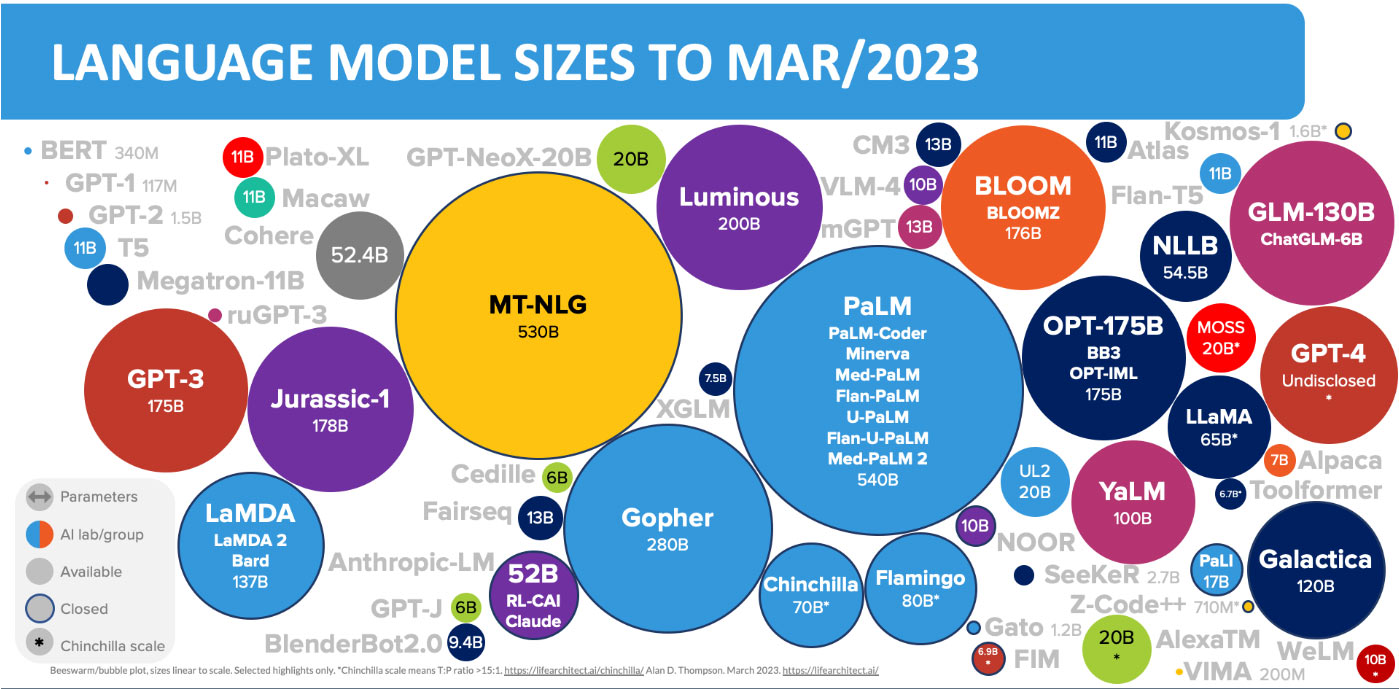
Zdroj infografiky: lifeArchitect
