Obecný úvod do umělé inteligence — kapitola 6
Jak se umělá inteligence učí?
Strojové učení je jeden z nejpoužívanějších přístupů v oblasti umělé inteligence. Cílem jeho metod je odhalit vzory vyskytující se v datech. Místo toho, abychom stroji přesně popisovali nějaký postup, ukážeme mu velké množství příkladů, ze kterého se sám naučí, jak vykonávat konkrétní úlohu.
Co vlastně strojové učení znamená?
Stejně jako se člověk umí učit z příkladů a zkušeností, jsou toho schopny i člověkem vytvořené stroje. Rozdíl je v tom, že metody strojového učení nemají přehled o okolním světě a dokážou se zatím učit jen z dat, která jim byla předložena.
Lidé se občas ztrácejí v pojmech strojové učení a umělá inteligence. Řada systémů umělé inteligence je postavena právě pomocí strojového učení, ale nejedná se o jediný způsob. Vztah mezi těmito pojmy ilustruje následující obrázek.

Strojové učení přináší zásadní změnu ve způsobu, jakým vytváříme stroje. Místo toho, abychom jim přesně popisovali nějaký postup (algoritmus), ukážeme jim velké množství příkladů (nebo je necháme metodou pokus/omyl získávat zkušenosti), ze kterých se samy naučí, jak vykonávat konkrétní úlohy.
Představte si to na příkladu robotů, které bychom chtěli naučit hrát fotbal. Pokud bychom se snažili napsat algoritmus, který by popisoval všechny situace na hřišti a jak na ně mají roboti reagovat, bylo by to velmi zdlouhavé, ne-li nemožné. A tak místo toho vytvoříme pro roboty program, který je schopen se z mnoha příkladů naučit hrát fotbal sám. Třeba takhle:
Model strojového učení
Takto se nazývá program, který se z mnoha příkladů učí, jak řešit různé úlohy. Učení probíhá ve dvou fázích — trénování a testování. V trénovací fázi ukazujeme modelu množství příkladů (videa, obrázky, texty…), na nichž se učí tím, že vyhledává vzory (podobnosti). V testovací fázi ukazujeme modelu příklady, které ještě nikdy neviděl, a zjišťujeme, jak dobře funguje.
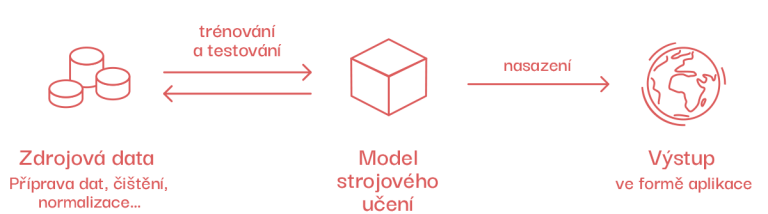
Co je zapotřebí k vytvoření modelu
K naučení modelu vždy potřebujeme data. Pod pojmem data si můžete představit například tabulku, složku obrázků, složku textů. Ve většině případů obsahují data člověkem přiřazenou výstupní hodnotu (anotaci), jako v předchozím případě, kde byla výstupní hodnota (pes nebo kočka). Můžeme mít různě velké množství dat, zpravidla ale platí, že s větším množstvím (kvalitních) dat roste kvalita predikcí modelu.
Daty se snažíme pokrýt všechny možné scénáře, s kterými se model později ve svém životním cyklu může setkat. To pomáhá modelu k takzvané generalizaci, tzn. schopnosti modelu predikovat data dříve nespatřená.
Pro jednoduché modely nám stačí několik desítek datových vzorků. Složitější modely, například neuronové sítě, jsou běžně trénovány i na tabulkách s miliony řádků. Není snadné poznat, zda model funguje (generalizuje) správně. V některých oblastech již modely dosahují výsledků srovnatelných s tím, jak by danou úlohu řešil člověk.
Příklady strojového učení v praxi
Už dnes se s aplikovanými metodami strojového učení setkáváme dennodenně. Například mezi každým dotazem a odpovědí na Google vyhledávači stojí model, který porovnává význam vašeho dotazu a textů na existujících webových stránkách (zdroj). Dále se můžeme setkat se strojovým učením například v online obchodech, kde umělá inteligence doporučuje zákazníkovi produkty, o které by mohl mít zájem (zdroj), nebo na YouTube, který se snaží udržet vaši pozornost doporučováním videí, která by pro vás mohla být zajímavá (zdroj).
Pokud bychom chtěli vytvořit pomocí tohoto typu strojového učení aplikaci, která rozpoznává psy a kočky, museli bychom nejdříve systému umělé inteligence říci, na kterých obrázcích jsou kočky a na kterých psi (tzv. anotovat data). Lidé tedy plní úlohu učitelů, podle čehož se tento přístup nazývá.
Po rozdělení obrázků na kočky a psy bychom natrénovali model strojového učení a poté bychom mu ukazovali obrázky koček a psů, které ještě nikdy neviděl.
Sledovali bychom, zda zvíře určil správně. Pokud ne, vylepšili bychom datovou sadu a natrénovali model znovu.
Někdy může být velmi zdlouhavé, nákladné či přímo nemožné všechna data anotovat. V takových případech využíváme strojové učení bez učitele.
Tento typ programu si vyhledává podobnosti (vzory) sám a vstupní data poté dokáže rozdělit do shluků (anglicky cluster), abychom se v datech my lidé lépe vyznali — a především pak snadno určili, co který shluk znamená.
Někdy necháme stroje, aby něco zkoušely samy (metodou pokus/omyl), a následně jim dáváme zpětnou vazbu skrze tzv. politiky. Stroje si na základě zpětné vazby (skrze politiky) vyvíjejí strategie chování.
Kapitoly příručky
Proč vést děti k poznávání umělé inteligence
Jak vidí umělou inteligenci děti
Stručná historie umělé inteligence
Co to vlastně je umělá inteligence
K čemu nám umělá inteligence slouží
Jak se umělá inteligence učí
Bez dat by to nešlo
Proč umělá inteligence diskriminuje
Etika umělé inteligence
Umělá inteligence a právo
Umělá inteligence a náboženství
Zranitelná AI
Ekologická zátěž umělé inteligence
---------------------
Educast AI dětem (YouTube)
Autor textu: Roman Dušek, Vojtěch Jindra
Editor: Eva Nečasová, Bertík Ullrich
Odborní garanti: Pavel Kordík, Jiří Materna
Datum poslední revize: 02/24
Doporučujeme k dalšímu studiu

bezplatný certifikovaný kurz
Bezplatný online kurz v češtině určený každému, kdo se chce dozvědět, co to je umělá inteligence, čeho lze a nelze jejím prostřednictvím dosáhnout a jak ovlivňuje naše životy. Pro účast v kurzu nejsou zapotřebí pokročilé znalosti matematiky ani znalost programování. Do českého prostředí kurz přináší prg.ai. Přejít na kurz →
Pilotní vzdělávací program Umělá inteligence do základních škol 2022/23 realizuje Pražský inovační institut
v rámci projektu iKAP II —
Inovace ve vzdělávání. Registrační číslo: CZ.02.3.68/0.0/0.0/19_078/0021106.

AI dětem © 2022. Využíváme cookies pro měření návštěvnosti webu.
Všechny vznikající metodiky podléhají licenci Creative Commons 4.0 Mezinárodní Licence.

AI dětem, z.s.
IČ: 17914582
Datovka: 4czjq6u
Číslo účtu: 2002446742/2010
Poptáváte vzdělávací akci či spolupráci?
Ozvěte se Kláře na: klara@aidetem.cz
Další kontakty naleznete v sekci Lidé.